
The IaC Conventions Nobody Shares — and Why They Matter Most

Every few weeks there is a new agent or "skill" that promises to generate enterprise-ready infrastructure-as-code from a paragraph of description. Describe your workload, get back hub-spoke Bicep or Terraform with private endpoints and a landing zone. I write Bicep with AI assistance every working day (and often also non-working days). Claude Code and Copilot are open in front of me constantly, and a large share of the templates I ship started as something a model drafted. So I am exactly the person these tools are built for. And the part they are proudest of is the part I do not want them to do.
The tools are good at the part I don't need
Credit where it is due. Microsoft has a public repo https://github.com/microsoft/azure-skills and one of the skills in there, the azure-enterprise-infra-planner, is a genuinely good example of the genre. It aligns a proposed design to the Well-Architected Framework. It understands hub-spoke topologies, landing zones, multi-region disaster recovery, and private endpoints. It stops and asks for approval before it writes any code, and it checks SKU and resource pairings against each other so you do not end up requesting a combination Azure will reject. If you are starting from a blank slate and want a competent first pass at an architecture in Bicep or Terraform, it is worth studying. The engineering behind it is real and I am not pretending otherwise.
It works to make a resource, or an architecture, enterprise-ready. It never looks at the repository itself: structure, versioning rules, changelog discipline, the exact formatting of parameter descriptions, whether you are reusing a shared type instead of inventing the sixth near-identical shape for the same object. All of that sits outside its scope, reasonably, because none of it is universal. But that layer, the one nobody is generating for you, is where a codebase either survives a few years of contributors or quietly rots. You can redraw an architecture in an afternoon. Unwinding five conventions for the same object takes months.
I already made that decision
There is a more basic objection underneath my reluctance. I do not want an agent reading the Well-Architected Framework and deciding how a resource should look. We already decided that. We sat down, we argued, we picked constraints for a specific case with specific requirements, and those constraints are not the ones a general best-practices pass would arrive at. Clients pay because their environment is not the generic case, and a best-practices pass optimizes for the generic case. I want to own every step of the architecture decision myself.
A skill that re-derives best practices on every run is more useful to me as a research assistant than as a code generator. I keep one of those around for exactly that: go read the current guidance, summarize the tradeoffs, tell me what changed since last year and show me the exact articles underlining those statements. That is a job I am happy to hand off. For IaC it is the wrong job. The design is already settled; the harder question is what a single template should even contain.
A template is a lifecycle
These skills emit code with no clear idea on how those resources fit into a lifecycle. A storage account, a VM, a network security group, a vnet, each one correct on its own. That is not how I build a template. When I start one I am not making a list of resources. I am deciding which of them belong together as a single unit: what gets created and destroyed as one thing, what shares a lifecycle, and in what order it would all have to come back.
The honest test is a disaster scenario. A good idea when creating a new template is to think what other resources would need to pre-exist and in what order what should be deployed. If this environment were gone tomorrow, could I recreate it from A to Z, in sequence, without anyone having to remember which piece depends on which? The vnet has has to exist before I wan't to add a subnet for a given application. A generator that hands me a flawless code knows none of that, because the ordering is not a property of the resource. It is a property of the system, and the system is ours to design.
Before I write a line of a template I usually sketch it, just for myself, so I can see how the pieces actually sit together first.
Three of them this template depends on and must only be referenced as existing, because they belong to other lifecycles: (yellow)
- the vnet
- the storage account
- a user-assigned managed identity
And the ones it actually creates and owns: (grey)
- a subnet inside that existing vnet, and the VMs that sit in it
- SFTP local users, their certificates, and a couple of blob containers on the existing storage account
- an app registration, and a role assignment that wires the identity to what it needs
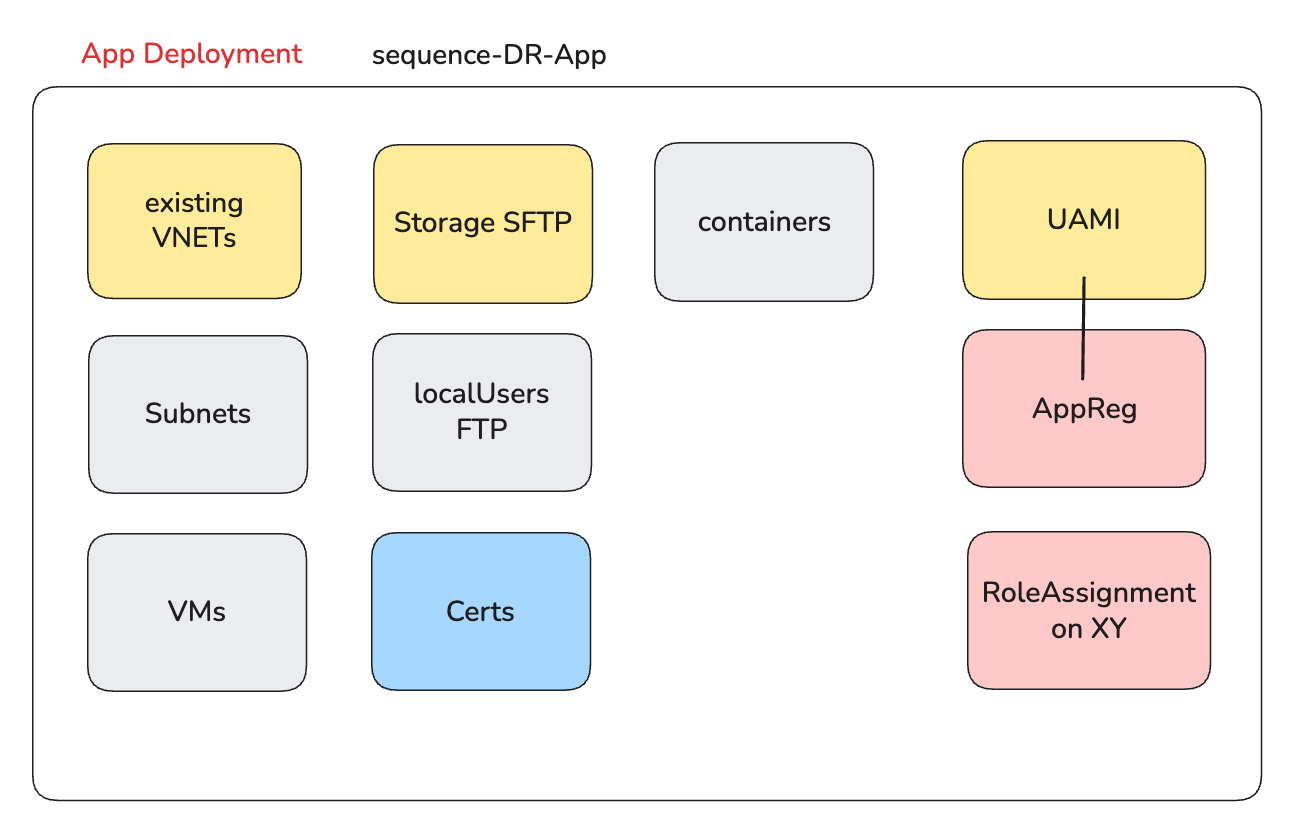
The vnet, the storage account, and the identity were each deployed earlier, by other templates, probably owned by other teams on other cadences. So the template has to be explicit about that split: what it owns, and what it only borrows. Get the line wrong and either you cannot tear the app down cleanly, or you recreate a vnet that half the estate sits inside.
That is what the colors are for. Yellow is a pre-existing resource from another lifecycle that this template only reads. Red I mark for something the template creates that needs more than Contributor to deploy (to make sure that we deploy with least-priviledge rights): the app registration and the role assignment both touch identity, so the deployment principal needs rights beyond the default, and marking that up front tells me where the easy path stops. Five minutes in Excalidraw surfaces the ordering and the permission boundaries before I have written anything I would later have to unpick.
Drawing those boundaries is the work, and it is precisely the part no resource generator is even looking at.
Brownfield is where it gets hard
Greenfield is the easy case, and it is the one every demo shows: an empty subscription, clean naming, nothing already in the way. Real environments are brownfield. Resources were clicked into existence in the portal over several years, the naming is inconsistent, and a good share of them predate any convention anyone would defend today. The moment a template has to manage resources that already exist, it forces a choice the generator never has to face.
The choice is this: do we write exceptions and overrides into our patterns to absorb whatever is already there, or do we clean up production first and bring it under management afterwards? Both are expensive. Exceptions pollute the pattern for good, so every future reader has to learn why this one resource is special. Cleanup is a migration, with its own downtime risk and its own blast radius. There is no default answer. It depends on the resource, the client, and how much the inconsistency will actually cost you later.
And once you decide to manage something that already exists, you have to know what changing it will do. If the code wants to recreate a public IP, where is that address already in use? A firewall rule, a VPN tunnel another customer connects through, a DNS record, an allow-list maintained by a team you have never spoken to. That question has nothing to do with the resource definition and everything to do with the rest of the estate, sometimes an estate you do not control. That is a cloud engineering and architecture call, and it does not hand off to a model looking at one resource through a straw.
A prompt is probabilistic
Say I have made all those calls: the lifecycle boundaries, the deployment order, what we do with the brownfield mess. The next problem is keeping them made, and that is where a prompt lets me down. A prompt is probabilistic. If your conventions live in natural-language guidance that a model interprets fresh each time, nothing guarantees the same prompt produces a comparable result a month from now. Different model version, different contributor, a slightly reworded instruction, and the output moves. Not by much on any single run, but enough that after six months you have three flavors of the same module and nobody can say which one is canonical. I want rules that fire identically every time, no matter who or what edits the file, not suggestions a model weighs against its own priors and might overrule.
What enforcement looks like in practice
Let me make that concrete with the conventions I actually enforce in one enterprise codebase I work in. None of it is shareable as a generic skill, which is rather the point.
Versioning is the spine
The team decided once, deliberately, when a change is a patch, when it is a minor, and when it is a major, and that one decision got wired into every workflow, skill, automation, and pipeline downstream. Modules use semantic versioning. The repository-wide changelog uses calendar-based release headers to group solution releases together. There is a promotion flow from a latest, development-facing repository into a stable, production one, with development tags, release-candidate tags, an explicit promotion step, and a build agent that handles the auto-merge. If I had to name the single most important thing in the entire setup, it is versioning. If the version rule is ambiguous, every downstream automation inherits the ambiguity.
So the version is not allowed to be ambiguous. A module's version lives in three places, and all three have to agree: the metadata file, the metadata line inside the template, and the top entry of the changelog.
// metadata.json
{
"version": {
"major": 1,
"minor": 0,
"patch": 2
}
}
metadata name = 'Subnet'
metadata owner = 'MFL'
metadata description = 'Deployment eines Subnets in ein VNET'
metadata version = '1.1.1'
metadata type = 'Module'
## 1.0.1 - 02.06.2026
Features(MFL):
- Optimierung einzelner Parameter (optional / mandatory / default values) & deren Logik
- `networkSecurityGroup`
- `routeTable`
- `delegations`
- `serviceEndpoints`
Nobody keeps three files in sync by hand under PR pressure, so they don't have to. A version-bump skill updates all three in one step. And if they disagree anyway, a CI gate catches it before a human looks at the PR:
✗ version-consistency
metadata.json 1.4.0
main.bicep 1.4.0
CHANGELOG.md 1.3.0 ← no entry for 1.4.0
merge blocked
The changelog format is fixed the same way: newest entry on top, a category-and-initials prefix on each line, one date format. I wrote up the mechanics of that version check on its own, if you want them: [[Catch Version Inconsistencies Before They Break Your Bicep Deployments]].
Descriptions, enforced to the character
Touch a parameter description or a property on a user-defined type and it has to take one exact shape. There is the right way, and there is only the right way:
@description('''

Base name of the virtual network, without prefix or suffix.
- Example: `vnet1`
''')
param parVnetName string
A model will not produce that reliably on its own, because it is not a best practice in any universal sense. It is glue between this repo's conventions and this repo's docs pipeline, and it only exists because we built both. So the convention is written down where the agent has to load it before it touches a file:
---
paths: ["**/*.bicep"]
---
Editing an @description() decorator:
- Line 1 after ''' is the shields.io badge: orange = required, green = optional.
- Blank line, then one description sentence.
- Then Default / Example / Hint, in that order. Values in backticks.
- A space after ''' is mandatory or the badge will not render.
- Two-space indentation on nested type properties.
That file loads automatically whenever a Bicep file is in play. The model does not get to decide the format. It gets told.
Reuse before you create
Type reuse runs before creation, not after. Before anyone adds a new user-defined type, the setup checks whether a similar shared type already exists that would be better to refactor toward, so the codebase does not slowly collect slightly different versions of the same shape. There are validators that flag a local type duplicating a shared one, an inline list of values duplicating a shared enum, or a hardcoded GUID where a named role should be resolved centrally instead.
How it's actually held in place
What holds all of this together is unglamorous machinery rather than a prompt. Path-scoped rule files fire automatically when a particular kind of file is edited, so the right conventions load for whatever you are touching. Validation skills run a couple dozen pass, warn, and fail checks before a PR is allowed through. A version-bump skill updates the three version locations and the changelog header in one atomic step so they cannot disagree by accident. And CI pipelines do the gatekeeping: blocking merges, validating the PR-title format, cutting git tags, regenerating docs, running deployment-snapshot drift checks.
That is deterministic enforcement. It does not care which model drafted the code or which contributor opened the PR. It produces the same verdict on Tuesday that it produced last month, and that repeatability is the whole value. The model drafts the Bicep. The CI gates decide whether it gets merged.
Why none of this gets shared
The content that gets shared online is greenfield architecture, because greenfield architecture demos beautifully and generalizes well enough to write a blog post about. The things that actually keep a codebase healthy across months and years do not demo at all: the lifecycle boundaries, the deployment order, the brownfield judgment calls, and the dull convention layer that holds the rest in shape. None of that travels. It is boring, specific to one team's decisions, and it leaves no clean before-and-after screenshot. Nobody gets applause for a post about a mandatory leading space after a triple-quote, or about why a public IP was deliberately left out of a template. But those are the calls that matter most to a repo that has survived eighteen months.
I am happy to have AI generate the boilerplate, draft the module, save me the typing. What I am not handing it is the deciding: what belongs together, what order it comes back in, what we do with the resources that are already there, and how this particular client's environment should be shaped. We already had those arguments internally and settled them. The drafting is cheap now. The thing I am still paid for is keeping six months of those drafts from fragmenting into six dialects.