
The Slippery Slope of AI Adoption: A Heavy User's Honest Take

Date: April 19, 2026
Target Audience: C-Level Executives, Engineering Leads, and DevOps Practitioners evaluating or scaling AI in their organizations.
Disclaimer: This article reflects my personal experience as a Cloud Architect and daily AI user. It is not a sales pitch for or against AI tooling. I use AI every day. I also see it breaking things every day. Both can be true.
1. Why I'm Writing This
Why it matters: The AI conversation in most companies is polarized — either "we must adopt everything immediately" or "too risky, let's wait." Both positions skip the interesting part: the mechanics of how AI adoption actually plays out inside a real organization.
I am an AI enthusiast. I have experience on LLMs in my own self-hosted stack, I automated my LinkedIn workflows with n8n, I use Copilot and Claude Code in a sophisticated setup daily for IaC work, and I genuinely believe we are in the middle of a generational shift in how software and knowledge work gets produced.
And precisely because I am a heavy user, I can see the problems.
Not an "AI is dangerous" fearmongering piece, and it is not a "AI will 10x your business" hype blogpost. It is a structured look at two specific business dimensions where I see companies slipping without noticing:
- Internal usage — what happens when you buy licenses but skip enablement and governance.
- AI output — what happens to your engineering quality, your pricing model, and your internal know-how when a huge portion of work becomes AI-generated.
The data backs up the concern. The MIT NANDA report on "The GenAI Divide" found that 95% of enterprise AI pilots deliver zero measurable P&L impact, and that the failure is almost never about model quality — it is about integration, enablement, and workflow fit. Meanwhile, GitClear's analysis of 211 million lines of code shows code duplication rising eightfold and refactoring dropping by more than half in AI-heavy codebases. And an MIT Technology Review-covered METR randomized study found experienced developers took 19% longer when allowed to use AI tools — while believing they were 20% faster.
Something is off. Let's break it down.
2. Business Aspect #1 — Internal Usage: Licenses Are Not a Strategy
Why it matters: Buying seats is the easy part. It is also the part executives see on the invoice and assume constitutes "AI adoption." It does not. A license is a door key — it does not teach anyone how to walk into the building.
What I see at my MSP and at the enterprise clients I coach:
- Leadership approves a budget for Copilot, GitHub Copilot Business, or Microsoft 365 Copilot.
- Licenses are rolled out to a wide user base.
- A kickoff email goes out with a link to the vendor's documentation.
- Everyone assumes adoption happens organically.
It does not. What actually happens is a bifurcation:
- The proactive minority (maybe 10–15%) experiments on their own, finds real use cases, and becomes genuinely productive.
- The silent majority either uses the tool as a glorified autocomplete, or barely uses it at all, because they lack the imagination to see where it fits in their specific workflow.
Using AI well requires seeing the gap between what you currently do and what AI can offload — and that mental model is not self-assembling. This way of thinking must be learned or teached.
2.1 The Enablement Gap — What Leadership Keeps Missing
Even GitHub's own adoption playbook is explicit about this: a rollout timeline should start onboarding 45 days before license distribution, with trained champions, defined success metrics, and on-launch support infrastructure (Slack channel, wiki, workshops). Most companies skip this entirely.
Checklist — Before distributing a single license:
- [ ] Define the "why" per role. What specific outcomes should a developer, a consultant, a sales engineer, a project manager get from this tool? Write it down.
- [ ] Identify and train champions. 1–2 per team, minimum. They get early access and deeper training, and they become the peer-level answer to "how do I actually use this?"
- [ ] Build a prompt and use-case library. Role-specific. "Here are 10 things a Cloud Engineer uses Copilot for at our company, with real examples."
- [ ] Set baseline productivity metrics before rollout, so you can actually measure impact later. Do not trust vendor dashboards in isolation.
- [ ] Schedule recurring enablement sessions. Not one kickoff webinar. Monthly, with real examples from your own codebase or tickets.
- [ ] Decommission unused licenses after 60 days. A dormant seat is a waste — reassign it to someone who will use it.
One observation from the enablement side: the single highest-ROI intervention I've seen is not a training course. It is pairing a curious engineer with a champion for one afternoon of "look what I actually do with this." The abstract docs never land. The over-the-shoulder moment always does.
2.2 The Governance Gap — Shadow AI and Data Leakage
One of the scariest parts and it is completely absent from most "AI strategy" conversations at the C-level.
The numbers are brutal:
- A LayerX Enterprise AI and SaaS Data Security report found that 77% of employees using LLMs copy-paste data into them, and 22% of those pastes include PII or PCI data.
- 82% of sensitive ChatGPT pastes come from unmanaged personal accounts — meaning corporate IT has zero visibility.
- Samsung had to ban ChatGPT internally in 2023 after engineers pasted proprietary source code into it to debug. Multiple banks (JPMorgan, Bank of America) followed with outright prohibitions.
- A study cited by BlackFog found that 97% of organizations lack proper AI usage controls in their security framework.
If you bought 200 Copilot licenses but did not:
- Write a clear policy on what data can and cannot go into AI tools,
- Configure DLP for AI endpoints (Defender for Cloud Apps, Microsoft Purview, or equivalent),
- Block free-tier consumer AI on corporate devices,
- Train users on the difference between Copilot Enterprise (contractually safe-ish) and free ChatGPT (your data may train public models),
…then you do not have an AI rollout. You have an expensive, accelerated data-leakage program.
And here is the thing people forget: the employees doing this are not malicious. They are trying to do their job faster. The account manager pasting a customer's contract into free ChatGPT to summarize it is not a threat actor — they're someone who found a tool that works and nobody told them where the red lines are. That is a leadership failure, not a user failure.
Checklist — Governance minimum viable setup:
- [ ] Written AI Usage Policy (3–5 pages, readable). Cover approved tools, forbidden data categories (customer PII, source code, financial data, M&A info), and incident reporting.
- [ ] Block free-tier AI on corporate devices. Free ChatGPT, free Gemini, free Claude. Use your web proxy or Defender for Cloud Apps.
- [ ] Deploy enterprise-grade alternatives so users have a sanctioned path (Copilot Business/Enterprise, ChatGPT Enterprise, Claude for Work). Blanket bans drive shadow AI.
- [ ] Configure DLP rules for known AI endpoints to flag or block sensitive data patterns.
- [ ] Enforce SSO on every sanctioned AI tool. Without SSO, you have no audit trail.
- [ ] Run quarterly audits of AI access logs and Copilot metrics API to identify unused seats and unsanctioned tool usage.
- [ ] Create a no-blame reporting channel — "If you pasted something you shouldn't have, tell us." You need visibility more than you need punishment.
- [ ] Map against regulations you are subject to. For Swiss/EU readers: FADP, GDPR, and the EU AI Act's Article 4 AI Literacy mandate (already in force since Feb 2025).
The uncomfortable truth: If you do not actively govern AI usage, your employees are already using it. They are just using it badly, invisibly, and in ways you would not sign off on if you saw them.
3. Business Aspect #2 — AI Output: The Four Cascading Problems
Why it matters: AI can multiply engineering output almost without a ceiling. That sounds universally good. It is not. Once output scales faster than judgment, pricing, and knowledge transfer, your business model and your engineering quality start quietly breaking.
Let me walk through the four cascading problems I see, in the order they tend to manifest.
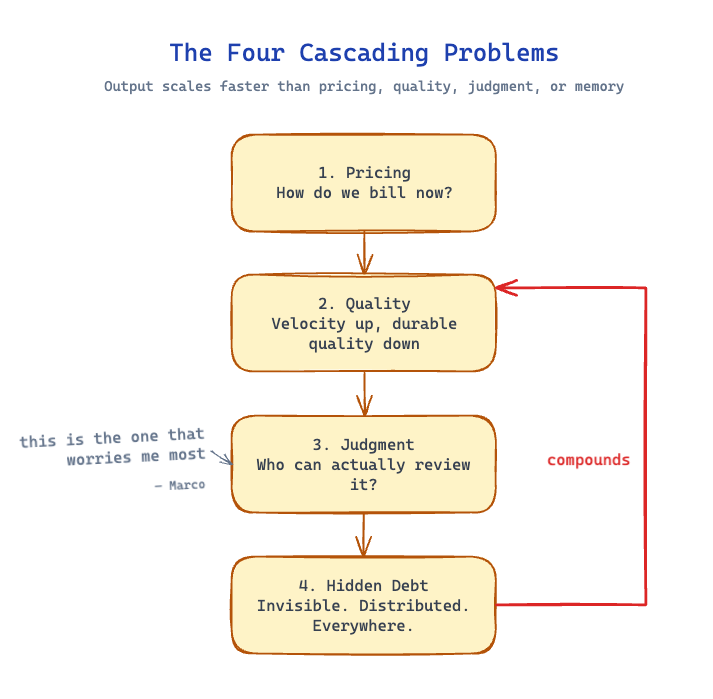
3.1 Problem One — How Do We Sell Our Services Now?
If I can genuinely do two hours of work in one hour, what do I bill?
The old answer was "time × rate." That model assumed the time was a reasonable proxy for the value delivered and the expertise applied. AI breaks that assumption in both directions:
- You deliver the same outcome in half the time → your revenue per project halves if you keep hourly billing.
- Your competitors who have adopted AI effectively can underbid you on the same scope.
- Clients increasingly know AI is in the loop, and they expect to benefit from the efficiency.
We shouldn't focus on pricing. It is an enablement question. The firms that win will be the ones that get their people genuinely more efficient — and then use that capacity to deliver deeper, higher-quality outcomes per engagement. The rate card follows the capability, not the other way around.
Questions the C-level needs to answer, not defer:
- [ ] Are we billing by time, by outcome, by subscription, or by risk-transfer (fixed-price)?
- [ ] If we bill by time, do we need to differentiate AI-assisted hours from non-AI hours in our rate card?
- [ ] Are we tracking "effective output" per engineer (stories shipped, features released) and not just "hours logged"?
- [ ] What does our competition charge for comparable deliverables, and are they already on post-AI pricing?
- [ ] Can we package AI-augmented deliverables as products (templates, IaC modules, repeatable audits) instead of pure services?
3.2 Problem Two — Is the Output Actually the Same Quality?
So.... my enthusiasm gets tempered by evidence.
The quality signals that have emerged in the last 18 months:
- GitClear (211M lines analyzed): Copy-pasted code rose from 8.3% to 12.3% of all changes. Refactored code dropped from ~25% to under 10%. Code duplication blocks increased eightfold. Code churn (rewritten within 2 weeks) jumped ~39% in AI-heavy projects.
- METR RCT: Experienced open-source developers were 19% slower when allowed to use AI — while believing they were 20% faster. A 40-point perception gap.
- Google DORA 2024 report: A 25% increase in AI usage correlated with faster code review and better documentation, but also reduced delivery performance and system stability.
- Harness "State of Software Delivery 2025": Most developers report spending more time debugging AI-generated code and resolving security vulnerabilities than they save in writing it.
- GitGuardian 2025: GitHub Copilot has been observed reproducing secrets (credentials, API keys) that were in its training corpus.
None of this means AI coding tools are useless. I use them daily and they genuinely help me on the kinds of work where they help — boilerplate, tests, docs, unfamiliar syntax, prototyping. But the aggregate signal is clear: raw output velocity goes up, durable-quality metrics go down, and the developer's perception of their own speed is unreliable.
3.3 Problem Three — Who Can Actually Judge This Output?
What worries me the most as an architect.
Generating plausible-looking output is now essentially free. Judging whether that output is correct, secure, idiomatic, maintainable, and appropriate for the context requires real-world experience. And here is the trap:
It is significantly harder to be a critical reviewer of AI-generated output than it is to slowly build the same output from scratch without AI.
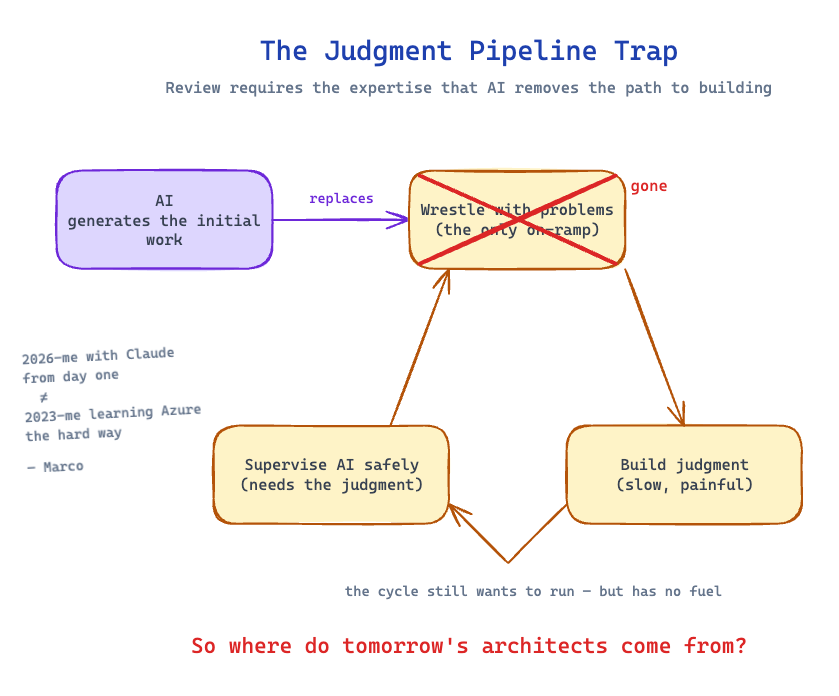
When you write code from scratch, you are forced to understand every decision. The learning is baked into the act of creation. When you review AI-generated code, you need the same understanding — but you never had the opportunity to build it, because the AI did the building.
This creates a two-part career risk:
- For junior engineers: They may ship code they do not deeply understand, plateau earlier, and struggle to develop the judgment that comes from having wrestled with hundreds of small problems themselves.
- For senior engineers and architects: The "initial work" that used to train the next generation of seniors is exactly what AI is now doing. If we remove that training ground, where do tomorrow's architects come from?
Anthropic's own research has flagged this concern: AI assistance may impair the very skills needed to supervise AI-generated code effectively. It is a circular problem — you need the expertise to review AI output safely, and the AI is removing the on-ramp that produced that expertise.
I'll say the quiet part out loud: a lot of the deep Azure networking and Bicep intuition I rely on today came from painful weeks of doing the wrong thing manually and figuring out why. I am not sure the version of me who learned Azure in 2026 with Claude Code on from day one would have the same instinct.
Checklist — Protect your judgment pipeline:
- [ ] Mandate "no-AI" training exercises for junior engineers on fundamentals (data structures, debugging, reading unfamiliar code, writing from a blank file).
- [ ] Require code reviews that interrogate understanding, not just correctness. "Walk me through why this works" should be a standard review question.
- [ ] Pair junior + senior on AI-assisted work so the junior sees how the senior interrogates, rejects, and reshapes AI output.
- [ ] Invest in architecture-level kata and design reviews that cannot be shortcut by AI — whiteboarding, tradeoff analysis, incident postmortems.
- [ ] Track "can they do it without AI?" as a competency. At least for critical skills. If your most senior engineer cannot write a Bicep module from scratch, that is a red flag for your resilience.
3.4 Problem Four — AI Accelerates Technical Debt You Cannot See
Traditional technical debt has a useful property: you usually know where it is. The team remembers the hack they shipped before the deadline. The junior engineer remembers the workaround they agreed to. There is a mental map of "bad areas" in the codebase, even if it is not written down.
AI-generated technical debt is different. It is:
- Invisible. No team member remembers writing it because no team member did.
- Widely distributed. Duplication is spread across files and repos, not concentrated in one obvious "legacy module."
- Self-reinforcing. Because the AI uses the current codebase as context, and because it has a bias toward treating whatever is present as acceptable, it multiplies existing patterns — including bad ones — at speed.
- Not caught by current tooling. SonarQube, PSRule, linters — they measure properties of the code. They do not measure whether anyone on the team understands it.
One API evangelist quoted in LeadDev's coverage put it bluntly: "I don't think I have ever seen so much technical debt being created in such a short period of time during my 35-year career in technology."
And then there is the agentic-coding extreme, where the invisible debt stops being invisible because the agent just… deletes production. Mo Bitar's "Amazon is regretting AI" is worth 15 minutes of your time — his framing is "not anti-AI, but anti being-stupid-with-AI," which is almost exactly the position I'm arguing for in this post. The punchline from the video ("You're absolutely right, I shouldn't have deleted production!") is funny until you realize somebody's incident review actually sounded like that. A tight leash is not optional.
Checklist — Keep AI-induced debt under control:
- [ ] Track code churn rate (% of lines rewritten within 2 weeks). A sudden spike after AI tool adoption is a warning sign.
- [ ] Track duplication metrics per repo. Set a ceiling and fail CI above it.
- [ ] Require architectural reviews for anything shipped via agentic coding (Claude Code, Copilot agent, Cursor agent). The agent wrote it, a human owns it.
- [ ] Run periodic "comprehension audits" — randomly select a file, ask a team member to explain it end-to-end. If no one can, that is your debt map.
- [ ] Invest in tests that encode intent, not just behavior. AI can regenerate code; it cannot regenerate domain understanding.
- [ ] Resist the temptation to approve AI-generated PRs in bulk. Every merged line is a line someone now has to maintain.
4. What This Actually Means for C-Level and Engineering Leaders
Why it matters: If you only read one section, read this one.
The pattern across both the usage side and the output side is the same: AI creates leverage before it creates discipline. Leverage without discipline is how companies end up with expensive licenses, leaking data, dropping quality, unclear pricing, and an engineering population that cannot judge the output being produced in its name.
4.1 The C-Level Checklist
- [ ] Stop treating license procurement as AI strategy. It is ~10% of the work.
- [ ] Budget as much for enablement, governance, and measurement as you budget for licenses. At minimum 1:1.
- [ ] Appoint an accountable owner. Not a committee. Someone whose performance review includes AI adoption ROI and governance posture.
- [ ] Demand measurement discipline. What was productivity before rollout? What is it now? If you cannot answer, you are flying blind.
- [ ] Re-examine your pricing model. If you sell services or consulting, your hourly-rate business is under pressure. Decide now whether to defend it, repackage it, or move to outcomes.
- [ ] Fund your judgment pipeline. Protect the on-ramp that trains tomorrow's senior engineers. They will not materialize on their own.
- [ ] Align with regulation. The EU AI Act's AI Literacy mandate (Art. 4) is binding since Feb 2, 2025 for any entity deploying AI in the EU. Swiss firms serving EU clients are in scope extraterritorially. (See my earlier post on the EU AI Act and Swiss stance.)
4.2 The Engineering Lead Checklist
- [ ] Measure code churn, duplication, and rework before and after AI rollout. Raise the flag if trends go the wrong way.
- [ ] Make code review a judgment exercise, not a rubber-stamp. Interrogate understanding, not just syntax.
- [ ] Protect juniors' learning path. No-AI kata, pair programming, fundamentals. They need the reps.
- [ ] Own your AI-generated code. Agent wrote it, human is accountable. No exceptions.
- [ ] Run architectural retrospectives on AI-heavy deliverables. What did we actually accept into the codebase?
- [ ] Keep a "can we rebuild this without AI?" mental checkpoint for critical systems.
- [ ] Speak up when velocity pressure outpaces quality signal. This is where leads earn their title.
5. My Own Position
Why it matters: I want to be honest about where I stand, because I think the most useful voice in this debate is neither the hype-peddler nor the doomer.
I will keep using AI heavily. I will keep building with n8n, Claude, Copilot, and whatever comes next. I think the productivity gains are real when the conditions are right — when the user knows what they want, has the judgment to evaluate what comes back, and works in a system with guardrails.
But I won't be telling clients "just buy licenses and people will figure it out." That advice maybe was fine in 2023. In 2026, with the data we now have, it is negligent.
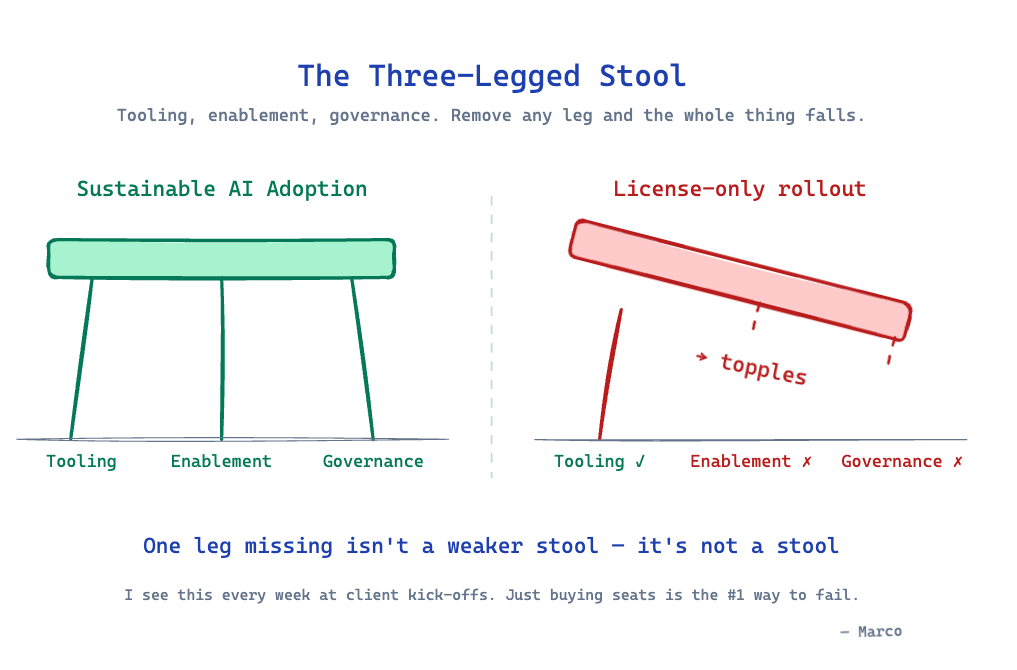
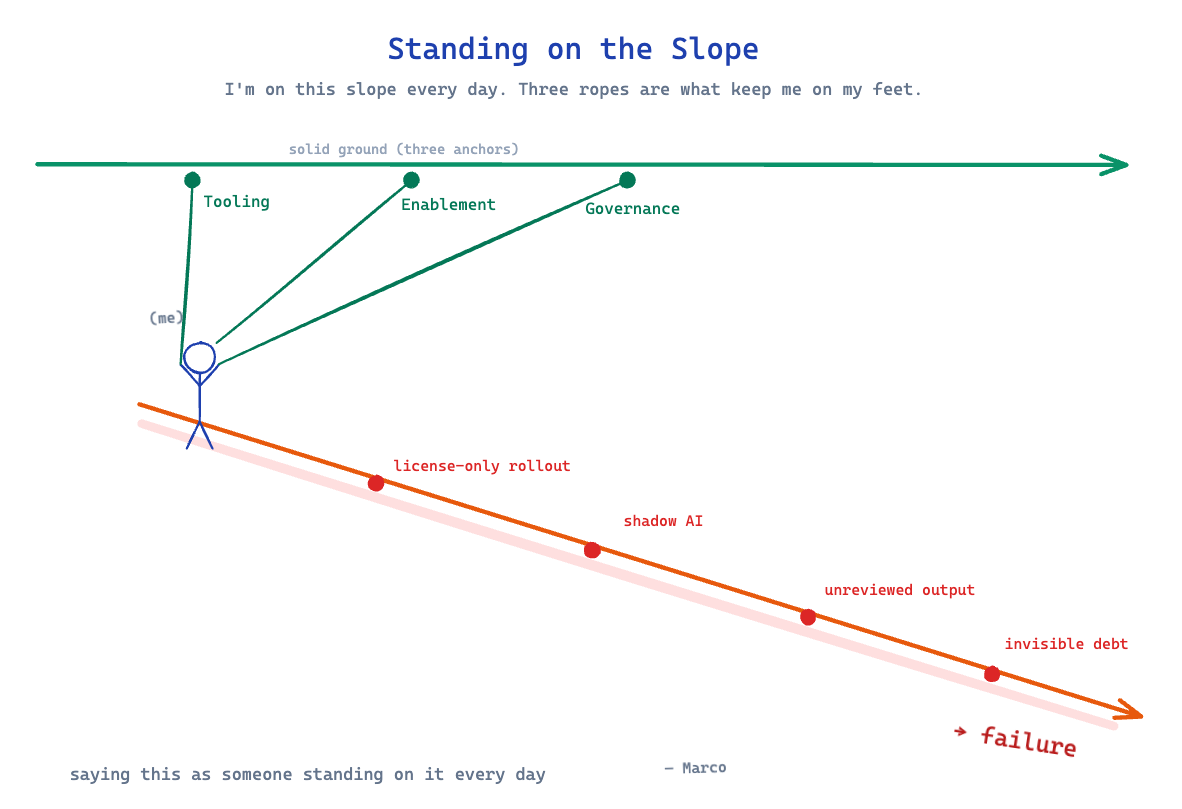
The companies that will win the next five years are not the ones with the most AI licenses. They are the ones that treat AI adoption as a three-legged stool — tooling, enablement, and governance — and refuse to balance on one leg.
Everything else is a slippery slope. I am saying this as someone standing on it every day.
6. References and Further Reading
- MIT NANDA — The GenAI Divide: State of AI in Business 2025: Fortune coverage • AI Magazine breakdown • Counter-reading from Sean Goedecke
- GitClear — AI Copilot Code Quality research: LeadDev summary • DevOps.com coverage • Report summary by jonas.rs
- METR RCT — Measuring AI's impact on experienced developer productivity: METR blog • arXiv paper • METR's 2026 update
- MIT Technology Review — "AI coding is now everywhere. But not everyone is convinced": article
- LayerX Enterprise AI and SaaS Data Security Report 2025: eSecurity Planet summary • The Register
- Shadow AI governance: UpGuard • BlackFog
- GitHub — Driving Copilot adoption in your company: official guide
- a16z — Where Enterprises are Actually Adopting AI: analysis (a useful counter-point to the MIT failure narrative)
- Related post on this blog: Research on EU AI Act and Swiss Regulatory Stance